本篇主要讲解如何通过 SQL 语句来进行数据库中表的 CURD 操作。
常说的 CURD 就是 增 CREATE 改 UPDATE 查 Retrieve 删 DELETE
单表基本查询
单表基本查询是指在 SQL 查询中仅涉及单个表的查询操作,而不涉及多个表的连接或联合查询。这种查询通常用于从单个数据表中检索、过滤、排序和汇总数据。
INSERT
INSERT 是 SQL 中的关键字,用于将新的数据行插入到数据库表中。这是一种用于添加新记录的重要操作,通常与 VALUES 子句或 SELECT 子句一起使用,具体取决于您要插入的数据来源。
在 students 表中增加两条数据。
1
2
3
4
5
6
-- 增加语句
INSERT INTO `students` (id, name, birthday, phone, age, sex, class_id)
VALUES
('508', '琦玉', '1999-1-1', '123456', 23, DEFAULT, 2),
('509', '杰诺斯', '1999-1-1', '123456', 23, DEFAULT, 2);
DELETE
DELETE 是 SQL 中的关键字,用于从数据库表中删除数据行。这个操作通常用于删除不再需要的数据或记录。
删除 students 表中 id = 502 的数据。
1
2
3
4
5
-- 删除语句
-- 需要注意添加条件
DELETE FROM students
WHERE id = 502;
UPDATE
UPDATE 是 SQL 中的关键字,用于修改数据库表中现有数据行的内容。这个操作通常用于更新表中的记录,以反映数据的变化或修正错误。
将 students 表中 id = 501 的这条数据的字段为 name 的值更改为 奥本海默。
1
2
3
4
5
-- 修改语句
-- 需要注意添加条件
UPDATE `students` SET `name` = '奥本海默'
WHERE id = 501;
SELECT
SELECT 是 SQL 中最常用的关键字之一,用于从数据库中检索数据。它用于查询数据库表以获取特定条件下的数据行,并将结果返回给用户或应用程序。
示例 1:选择表中的所有数据。
1
2
SELECT *
FROM employees;
示例 2:选择 user 表中的字段 id loginid loginpwd 并增加一个字段 abc。
1
SELECT id, loginid, loginpwd, 'abc' FROM `user`;
case
示例 3:选择 employee 表中的字段 id name,遇到 ismale 时,进行 case 判断,如果值为 1,则将查询结果显示为 男,否则为 女,以字段名 sex 结束。
1
2
3
4
5
6
SELECT id, `name`,
CASE ismale
WHEN 1 THEN '男'
ELSE '女'
AND sex
FROM `employee`
distinct
示例 4:选择 employee 表中的字段 location 去掉重复数据
1
SELECT DISTINCT location FROM employee;
distinct一般只去重一个字段,如果包含多个字段,则会去掉这两个字段都重复的数据
WHERE
= > < >= <=
选择 employee 表中的字段 id = 1 的数据,其他符号类似
1
2
SELECT * FROM employee
WHERE id = 1
IN
选择 employee 表中的字段 id = 1 或 id = 2 的数据
1
2
SELECT * FROM employee
WHERE id IN (1, 2)
IS & IS NOT
IS IS NOT 一般搭配 NULL 使用。
选择 employee 表中的字段 location 值 为/不为 NULL 的所有数据
1
2
3
SELECT * FROM employee
WHERE location IS NULL
-- WHERE location IS NOT NULL
BETWEEN
选择 employee 表中的字段 salary 值在 10000-12000 之间的所有数据
1
2
SELECT * FROM employee
WHERE salary BETWEEN 10000 AND 12000
LIKE
模糊查询
1
2
3
4
5
6
7
SELECT * FROM employee
-- 名字包含「王」
-- WHERE `name` LIKE '%王%'
-- 姓氏为「王」
-- WHERE `name` LIKE '王%'
-- '_'表示匹配一个字符,这里是只查找两个字的
WHERE `name` LIKE '王'
AND & OR
and 多个条件同时匹配
or 多个条件满足其一
1
2
3
4
5
6
7
-- 优先级 AND > OR
-- 姓氏为张的女士 (工资大于 12k 或 出生日期大于 1996-1-1)
SELECT * FROM employee
WHERE `name` LIKE '张%' AND
(ismale = 0 AND salary >= 12000
OR
birthday >= '1996-1-1');
ORDER BY
ORDER BY 用于数据的排序
ASC 升序,DESC 降序,优先级 SELECT > ORDER BY
根据 sex 升序,salary 降序排序,此处比较的 sex 为汉字会转换成 ASCII 码进行比较
1
2
3
4
5
6
7
8
9
10
11
12
13
SELECT *,
CASE ismale
WHEN 1 THEN '男'
ELSE '女'
END sex
FROM employee
WHERE `name` LIKE '张%' AND
(ismale = 0 AND salary >= 12000
OR
birthday >= '1998-1-1')
ORDER BY sex ASC, salary DESC;
LIMIT
LIMIT n, m 跳过 n 条数据 取出 m 条数据
分页查询公式:LIMIT (page - 1) * pageSize, pageSize
1
2
SELECT * FROM employee
LIMIT 2, 3
运行顺序 FROM > WHERE > SELECT > ORDER BY > LIMIT
连表查询
连接表查询是 SQL 查询的一种重要形式,它允许你从多个表中检索相关数据。在连接表查询中,你可以将两个或多个表关联起来,以便根据特定的关联条件获取相关的信息。以下是连接表查询的示例,展示了如何使用不同类型的连接来检索数据。
笛卡尔积
在数学中,两个集合 X 和 Y 的笛卡尔积(英语:Cartesian product),又称直积,在集合论中表示为
X x Y,是所有可能的有序对组成的集合,其中有序对的第一个对象是 X 的成员,第二个对象是 Y 的成员。
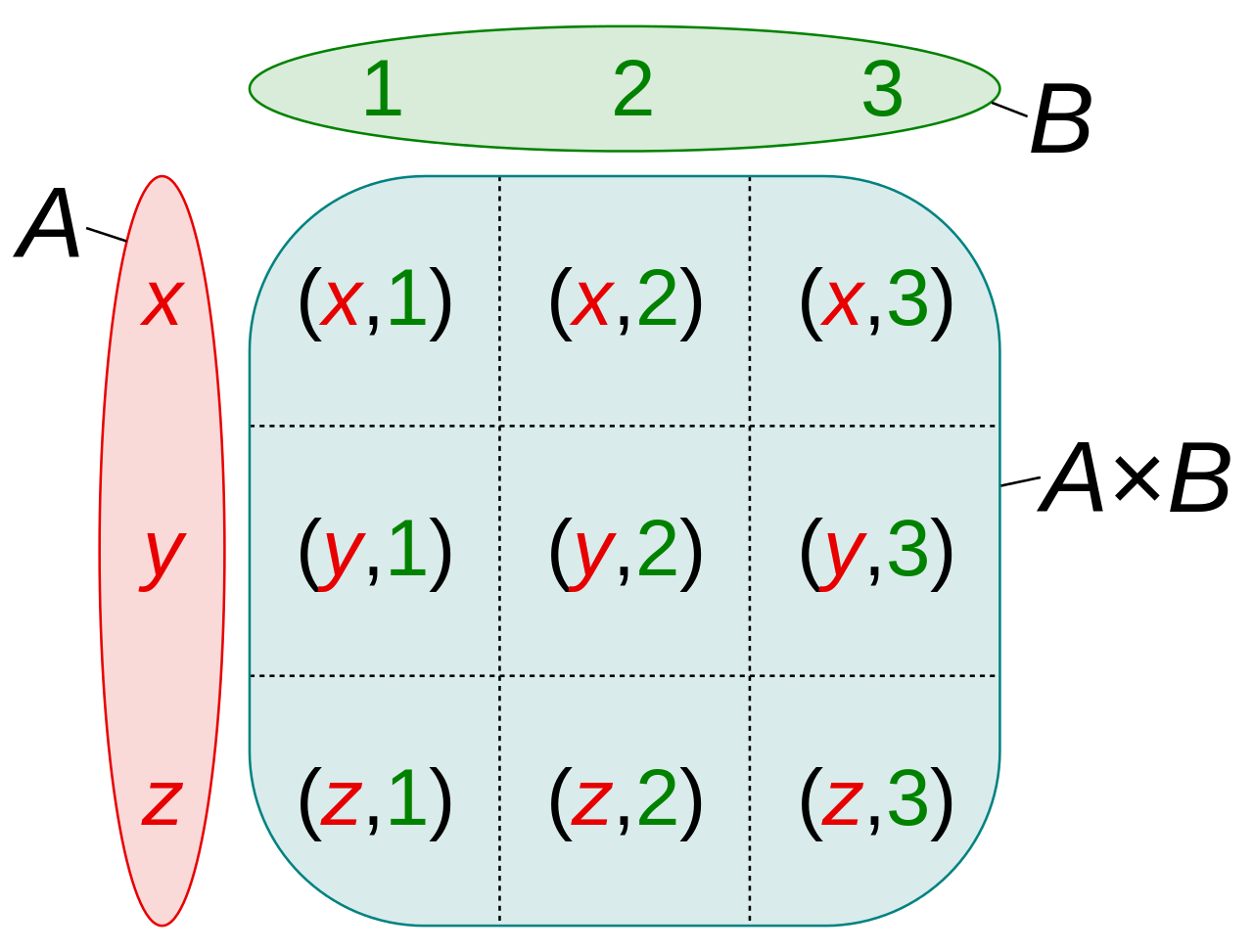
在 team 表中计算自己的笛卡尔积,取别名来区分主客场,并且过滤掉相同球队的主客场对阵。
1
2
3
SELECT t1.name as 主场, t2.name as 客场
FROM team as t1, team as t2
WHERE t1.id != t2.id
左连接 LEFT JOIN
左连接查询不到以左边为基准
基准的数据必须出现一次
1
2
3
SELECT *
FROM department as d LEFT JOIN employee as e
on d.id = e.deptId
右连接 RIGHT JOIN
右链接查询不到以右边为基准
基准的数据必须出现一次
1
2
3
SELECT *
FROM employee as e RIGHT JOIN department as d
on d.id = e.deptId
内连接 INNER JOIN
显示出所有员工的姓名、所属部门(显示部门名称)、所属公司(显示公司名称)
1
2
3
4
5
6
7
-- inner 内连接 常用 条件必须满足
SELECT e.`name` 员工姓名,
d.`name` as 部门名称,
c.`name` as 公司名称
FROM employee as e
INNER JOIN department as d on e.deptId = d.id
INNER JOIN company as c on d.companyId = c.id
函数
在 SQL 中,函数是用于执行特定操作或计算的命令或表达式。SQL 函数通常接受一个或多个参数,并返回一个值作为结果。SQL 中有许多内置函数,用于执行各种任务,包括数据操作、字符串处理、数学计算和日期处理等。
聚合函数:
COUNT(column_name):计算行数或满足条件的行数。SUM(column_name):计算数值列的总和。AVG(column_name):计算数值列的平均值。MAX(column_name):找出列的最大值。MIN(column_name):找出列的最小值。
字符串函数
CONCAT(string1, string2, ...):将多个字符串连接在一起。SUBSTRING(string, start, length):提取字符串的子串。UPPER(string)和LOWER(string):将字符串转换为大写或小写。LENGTH(string)或LEN(string):返回字符串的长度。TRIM(str):去除字符串首部和尾部的所有空格。LTRIM(str):从字符串 str 中去掉开头的空格。RTRIM(str):返回字符串 str 尾部的空格。
日期和时间函数:
CURDATE()或CURRENT_DATE():返回当前的日期。CURTIME()或CURRENT_TIME():返回当前的时间。NOW():返回当前日期和时间。DATE():提取日期部分。TIME():提取时间部分。DATEDIFF():计算日期之间的差距。TIMESTAMPDIFF(part, date1, date2):返回 date1 到 date2 之间相隔的 part 值,part 是用于指定的相隔的年或月或日等。part 取值为MICROSECOND SECOND MINUTE HOUR DAY WEEK MONTH QUARTER YEAR
数学函数:
ROUND(x,y):返回参数 x 的四舍五入的有 y 位小数的值。CEIL(number)和FLOOR(number):向上取整和向下取整。ABS(number):返回绝对值。POWER(base, exponent):计算幂运算。PI():返回 π 的值(圆周率)。TRUNCATE(x, y):返回数字 x 截短为 y 位小数的结果。
分组
在 SQL 查询中,使用 GROUP BY 子句可以对查询结果进行分组。分组是对具有相同值的列进行合并,并且通常与聚合函数一起使用,以便对每个分组执行聚合操作。
GROUP BY
GROUP BY 子句是 SQL 查询中用于分组结果集的重要部分。它将查询的结果按照一个或多个列的值进行分组,并对每个分组应用聚合函数(如 COUNT、SUM、AVG、MAX、MIN 等)以计算汇总信息。
HAVING
HAVING 子句允许您对分组后的结果集进行筛选。它通常与 GROUP BY 一起使用,用于筛选具有特定聚合计算结果的分组。
1
2
3
4
SELECT column1, aggregate_function(column2)
FROM table_name
GROUP BY column1
HAVING aggregate_function(column2) condition;
优先级
FROM>JOIN ... ON ...>WHERE>GROUP BY>SELECT>HAVING>ORDER BY>LIMIT。分组后,只能查询分组的列和聚合列。
子查询
子查询是一个查询嵌套在另一个查询中的查询,通常用于获取更复杂的数据或根据外部查询的结果来过滤内部查询的数据。子查询可以嵌套多层,根据需要进行组合。
1
2
3
SELECT first_name, last_name
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
练习
查询所有公司 8 年内入职的居住在星光大道的员工数量,要求显示其他公司,员工数量没有的为 0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
SELECT c.`name` as name,
CASE
WHEN res.number is NULL
THEN 0
ELSE res.number
END number
FROM company as c
LEFT JOIN
(
SELECT c.`id` as id, COUNT(e.id) as number
FROM employee as e
INNER JOIN department as d on d.id = e.deptId
INNER JOIN company as c on c.id = d.companyId
WHERE TIMESTAMPDIFF(YEAR, e.joinDate, CURDATE()) <= 8
AND e.location like '%星光大道%'
GROUP BY c.id, c.`name`
) as res on c.id = res.id